
Of Directories and inodes…
Earlier this year, a student asked me an interesting question, which I’ll paraphrase as such: “What’s the difference between files and directories in a Unix-like filesystem? And what role do the inodes play?”
The answer to this question, to me, wasn’t immediately obvious, so I started digging.
The Unix Filesystem
Unix-like operating systems (and nerds) have a specific mental image of the filesystem as an inverted tree with a root directory and an arbitrary number of subdirectories; here, leaf nodes in the tree are files, while the other nodes are directories. This model derives from the original UFS implementation, and it is a pretty clear and concise description of the Unix FS (if we ignore the fact that a whole portion of the tree can be masked by mounting another filesystem in that location, and that hard links can turn the tree into a cyclic data structure, causing absolute havoc). If you need a refresher on the basics, read this.
Here’s a cool visual representation of my /etc/X11 folder, courtesy of fsnav1.
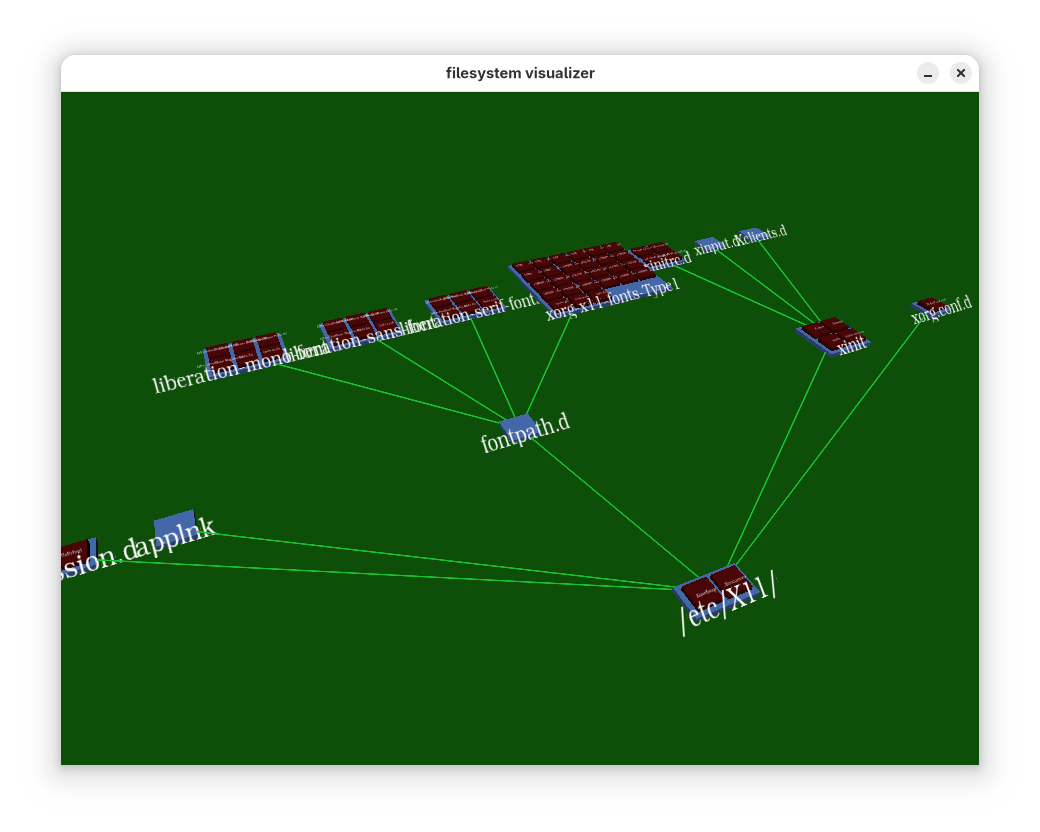
fsnav is inspired by the (very iconic) fsn file explorer of Jurassic Park fame, which ran on SGI Irix. Here is a nice screenshot of fsn in action, showing the whole /usr tree on an old Irix workstation.
However, several decades have passed since the inception of Unix, and several new ideas and ways to organize the files on disk have emerged. In particular, a lot of filesystems with complicated, enterprise-y feature sets started to emerge in the late 90s and early 00s (Sun’s Zettabyte File System (ZFS) is probably the most fitting example). While these FSes are very interesting in their own regard, they essentially expose the same tree structure to maintain compatibility with the Unix API2.
Data and Metadata
Whenever you use a filesystem to store something on disk, you’re not directly storing the contents of the file as a bytestream, but you’re leveraging the functionality provided by the FS to organize data so you can retrieve it more efficiently. This is the intended purpose for filesystems, but it has an interesting side effect: you need metadata! Metadata can be described as “data which is not your data per se, but is necessary to categorize it”, and includes the file name, creation and access times, permissions, in some cases file type or extension, links to the file, etc. Some of the metadata is hidden from the user because it’s used only internally to organize data on the disk (e.g., block size, number of blocks, a pointer to the block, etc.). Of course, the metadata must be stored separately from your data, while still having a list of pointers to the blocks where your file’s bytes reside.
Index Nodes
In the Unix filesystem, metadata is stored in Index Nodes (inodes), along with a list of blocks. You can consult Linux’s inode(7) manual page and FreeBSD’s FS(5) manual page for proper information regarding the usage and the structure of inodes. The ext4 docs are also a great read.
This is not what an
inodelooks like 😉

Directories, inodes, and whatnot
Back to the student’s question, we need to understand the relation between inodes and directories. We know that each file (i.e., data) has an inode (i.e., metadata) associated to it. Now, if the old saying “in Unix, everything is a file” holds true, then a directory must be a special kind of file… thus a directory has an inode!
We have to stop for a moment, and thank Aristoteles for the humble Syllogism… too bad we had to invent fuzzy logic to get on with our lives.
OK, so if a file is essentially an inode with a table of associated blocks, we can imagine a directory as an inode with a table of associated… something?
Yeah, pretty much: the BSD manpages clearly state that a directory is a file with a special flag set in its inode, which contains a special data structure called a “Directory Entry” (dirent). Again, the ext4 docs explain quite clearly how they implemented the dirent.
If you create a loop device and format it as ext4, you can see that stat reports that the directory occupies two blocks. I assume that the blocks contain the dirents for each file in the directory, including subdirectories, ., and ...
# dd if=/dev/zero of=test.img bs=1M count=128
# losetup -f test.img
# mkfs.ext4 /dev/loop0
mke2fs 1.47.2 (1-Jan-2025)
Discarding device blocks: done
Creating filesystem with 131072 1k blocks and 32768 inodes
Filesystem UUID: 2b335308-28c1-4a29-8d39-bb4a65954d1a
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Allocating group tables: done
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
# mount /dev/loop0 /mnt
# cd /mnt
# stat .
File: .
Size: 1024 Blocks: 2 IO Block: 1024 directory
Device: 7,0 Inode: 2 Links: 3
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Context: system_u:object_r:unlabeled_t:s0
Access: 2025-08-26 17:47:49.875152086 +0200
Modify: 2025-08-26 17:47:13.000000000 +0200
Change: 2025-08-26 17:47:13.000000000 +0200
Birth: 2025-08-26 17:47:13.000000000 +0200
# ls -la
total 13
drwxr-xr-x 3 root root 1024 Aug 26 17:47 .
dr-xr-xr-x. 1 root root 158 May 12 13:56 ..
drwx------ 2 root root 12288 Aug 26 17:47 lost+found
#
This absolutely seems to be the case; we can confirm this by creating as much empty files as we can and looking at the number of blocks:
# CNT=0; while touch f$CNT; do ((CNT++)); done
touch: cannot touch 'f32756': No space left on device
# stat .
File: .
Size: 773120 Blocks: 1510 IO Block: 1024 directory
Device: 7,0 Inode: 2 Links: 3
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Context: system_u:object_r:unlabeled_t:s0
Access: 2025-08-26 17:57:54.638494664 +0200
Modify: 2025-08-26 18:01:09.711893548 +0200
Change: 2025-08-26 18:01:09.711893548 +0200
Birth: 2025-08-26 17:47:13.000000000 +0200
#
The IO Block is unrelated, see here.
We can see that the number of blocks has grown significantly! The error message given by touch, however, does not make a lot of sense: how can we use 128MB by only creating empty files? Let’s see:
# df -h .
Filesystem Size Used Avail Use% Mounted on
/dev/loop0 115M 800K 105M 1% /mnt
#
Here, df seems to agree with us: we have only used up 800K of space, which is around 1% of our disk… what gives? We’ve used up all of our inodes! In fact, ext allocates a fixed number of inodes when you run mkfs: once the filesystem has been created, you cannot change their amount. Once again, we can use df to dispel any doubt we may have:
# df -ih .
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/loop0 32K 32K 0 100% /mnt
#
We’re clearly out of ISpace!
Fun fact: The first time I ran into this problem, I was trying to compile Gentoo on an HP 9000 D220 with only ~1GB of disk space. Yikes! I remember trying to add more
inodes only to realize that I had no space left for the actual files when I did that.
Other filesystems
What we’ve discussed so far applies to “traditional” filesystems, such as ext4 and UFS. Scalable filesystems that support dynamically sized pools such as ZFS or Btrfs, usually don’t have a fixed number of inodes, or use completely different mechanisms for metadata storage.
-
An example of this compatibility is the fact that both Solaris and FreeBSD support root-on-UFS and root-on-ZFS interchangeably, even if the two filesystems work in a completely different way under the hood. We will come back to this later. ↩